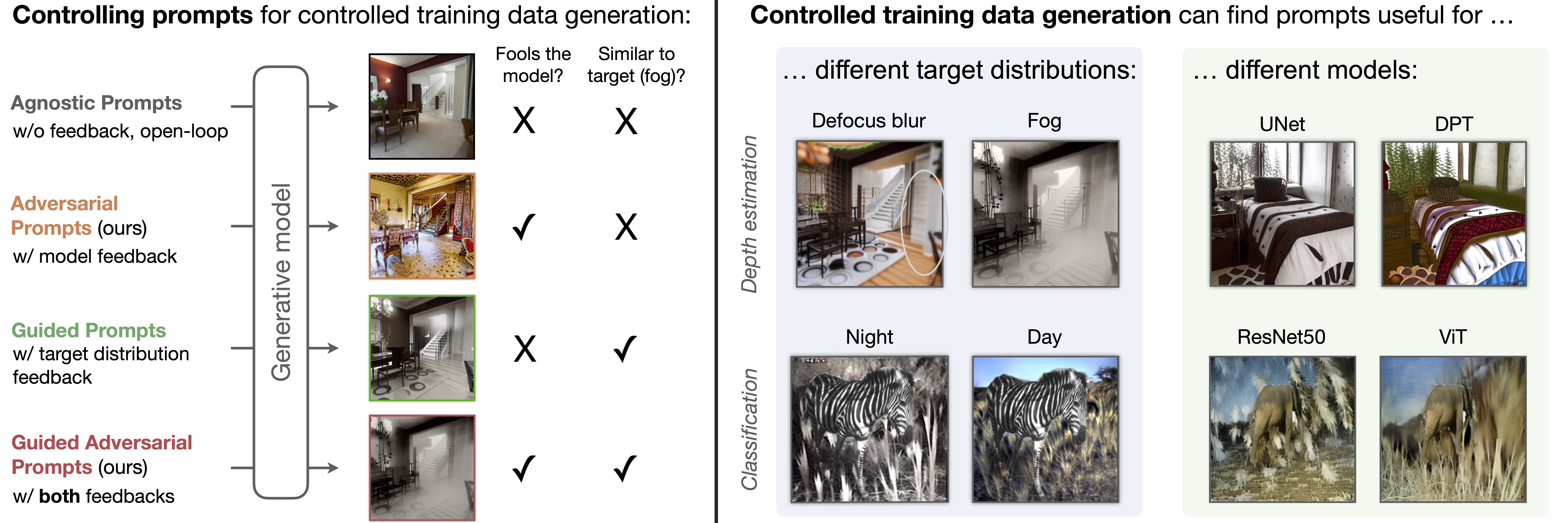
We present a method to control a text-to-image generative model to produce training data useful for supervised learning. Unlike previous works that employ an open-loop approach via pre-defined prompts to generate new data using either a language model or human expertise, we develop an automated closed-loop system that involves two feedback mechanisms. The first mechanism uses feedback from a given supervised model to find adversarial prompts that result in generated images that maximize the model's loss and, consequently, expose its vulnerabilities. While these adversarial prompts generate training examples curated for improving the given model, they are not curated for a specific target distribution of interest, which can be inefficient. Therefore, we introduce the second feedback mechanism that can optionally guide the generation process towards a desirable target distribution. We call the method combining these two mechanisms Guided Adversarial Prompts. The proposed closed-loop system allows us to control the training data generation for a given model and target image distribution. We evaluate on different tasks, datasets, and architectures, with different types of distribution shifts (corruptions, spurious correlations, unseen domains) and illustrate the advantages of the proposed feedback mechanisms compared to open-loop approaches.
We need aligned examples for supervised training, where an aligned example is an RGB image and its label. We employ the following two approaches.
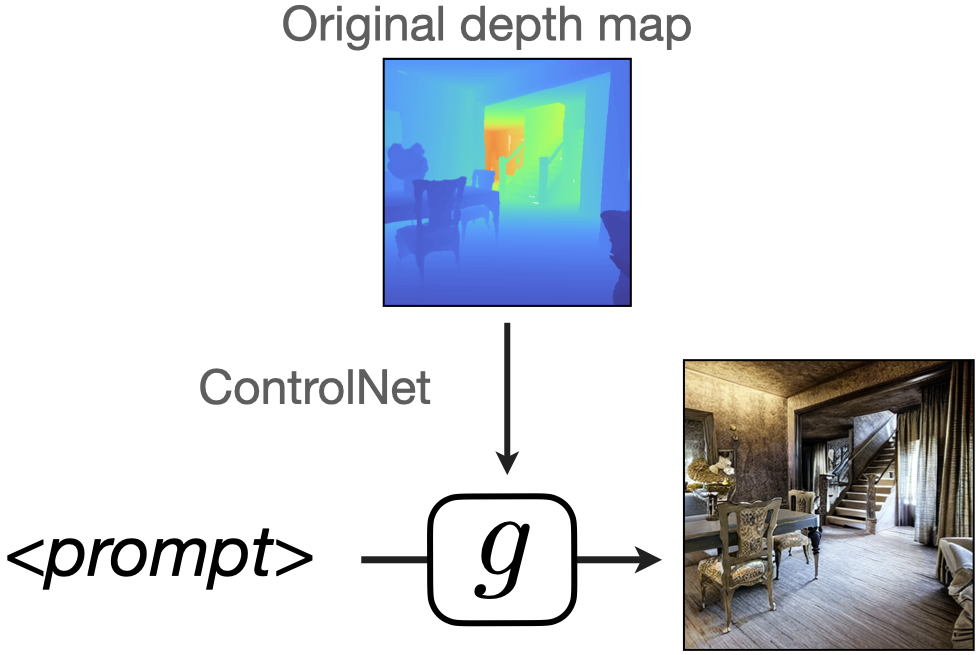
For the depth estimation task, we use the ControlNet model (Zhang L. et al.) with depth conditioning. We use the depth maps from the training dataset. ControlNet then generates an RGB image conditioned on the given depth map.

For semantic classification tasks, we utilize the foreground object masks and use an in-painting technique proposed by Lugmayr A. et al. that preserves the masked region throughout the denoising process, essentially keeping it intact.
Below we demonstrate how Adversarial Prompts evolve over optimization steps for a model trained on the Taskonomy dataset for the depth estimation task. As the number of optimization steps increases, images become more adversarial and some of the details get destroyed, resulting in generations less faithful to the original depth map. To avoid training on such examples, we apply early stopping and SDEdit (Meng C. et al.) image-to-image conditioning to generate training examples that are more faithful to the original label (see the paper for more details).


(Adversarial Prompt)
Hint: Drag the slider to change the adversarial optimization step. Use the buttons to explore different images.
Adversarial Prompts find new styles that fool a given supervised model. Below, you can explore different adversarial prompts for the depth estimation model trained on the Taskonomy dataset.
(Adversarial Prompt)
Hint: Drag the slider to change the adversarial prompt. Use the buttons to explore different images.
The following visualization shows adversarial prompts found for a model trained on the iWildCam dataset:
(Adversarial Prompt)
Hint: Drag the slider to change the adversarial prompt. Use the buttons to explore different images.
Unlike Adversarial Prompts, Guided Adversarial Prompts are informed of the target distribution of interest. Below, you can explore different guided adversarial prompts found for two target Common Corruptions domains Fog and Blur. Note how the generated images resemble the target domain.
Generated RGB
(Guided Adv. Prompt)
Target: CC Fog
Generated RGB
(Guided Adv. Prompt)
Target: CC BlurHint: Drag the slider to change the adversarial prompt. Use the buttons to explore different images.
iWildCam is a domain generalization dataset, made up of a large-scale collection of images captured from camera traps placed in various locations around the world. We seek to learn a model that generalizes to photos taken from new camera deployments. Here, we explore two guided adversarial prompts where the target is one of the novel test camera trap location, at daytime and nighttime.
Generated RGB
(Guided Adv. Prompt)
Target: Deployment 1
("grassy field")
Generated RGB
(Guided Adv. Prompt)
Target: Deployment 2
("at night")
Hint: Use the buttons to explore different images.
In the following example, we find guided adversarial prompts for a model trained on the Waterbirds dataset. Unlike the previous example, the target domain is the same as the training domain. The training domain has a spurious correlation: the waterbirds are on water and landbirds are on land. Note how the guided adversarial prompts tend to generate images missing in the original data, i.e. with the opposite correlation: waterbirds on land and landbirds on water. Training the model on these images allows to avoid the spurious correlation, see quantitative results below.
(waterbird on water)
(Guided Adv. Prompt)
(landbird on land)
(Guided Adv. Prompt)
Hint: Drag the slider to change the guided adversarial prompt. Use the buttons to explore different images.
Control (No Extra Data):
This fine-tunes the model on the original training data. This baseline is to ensure that the difference in performance is due to the generated data, rather than e.g., longer training or optimization hyperparameters
Agnostic Prompts:
We generate data with the prompt "nature" for Waterbirds, “a camera trap photo of {class name}” for iWildCam, and "room" for Taskonomy.
Guided Prompts:
These prompts are only informed of the target distribution.
For the classification task, we use the prompts from ALIA (Dunlap L. et al.).
For the depth task, we optimize for prompts using only the CLIP guidance loss.
Quantitative results on depth estimation. The table below shows the results on distribution shifts from Common Corruptions (CC), 3D Common Corruptions (3DCC) and Replica, from the U-Net and DPT models. The results from CC and 3DCC are averaged over all distortions and severity levels. The models were trained with different losses, \(\ell_1\) for the former and Midas loss for the latter, thus their performance is not comparable. Our method is able to generate training data that can improve results over the baselines on several distribution shifts. Finetuning on generated data from Adversarial Prompts with SDEdit gives better results than Adversarial Prompts under distribution shifts. Thus, also conditioning on the original image seems to be helpful for these shifts. For the DPT model, the trends are similar, Adversarial Prompts performs better than the baselines.
| U-Net | DPT | |||||
| Taskonomy | Replica | Taskonomy | ||||
| Shift | Clean | CC | 3DCC | CDS | CC | 3DCC |
| Control (No extra data) | 2.35 | 4.93 | 4.79 | 5.38 | 3.76 | 3.42 |
| Agnostic Prompts | 2.47 | 5.03 | 4.17 | 5.30 | 4.06 | 3.58 |
| Agnostic Prompts (Random) | 2.38 | 4.96 | 4.11 | 5.14 | 3.88 | 3.51 |
| Adversarial Prompts | 2.49 | 4.36 | 4.02 | 5.12 | 3.40 | 3.28 |
| Adversarial Prompts (SDEdit) | 2.59 | 4.20 | 3.88 | 4.96 | 3.35 | 3.25 |
Errors on the depth prediction task for a pre-trained U-Net and DPT model. U-Net losses are multiplied by 100 and DPT losses by 10 for readability.
Performance of Guided Adversarial Prompts against amount of generated data. The figure on the right shows the performance of our method on the defocus blur distribution shift over the amount of generated data added. Using Guided Prompts or Guided Adversarial Prompts results in a large improvement in performance, compared to Adversarial Prompts or the baseline with as little as 10 extra data points. This suggests that the guidance loss successfully guided the generations toward producing training data relevant to the distribution shift.
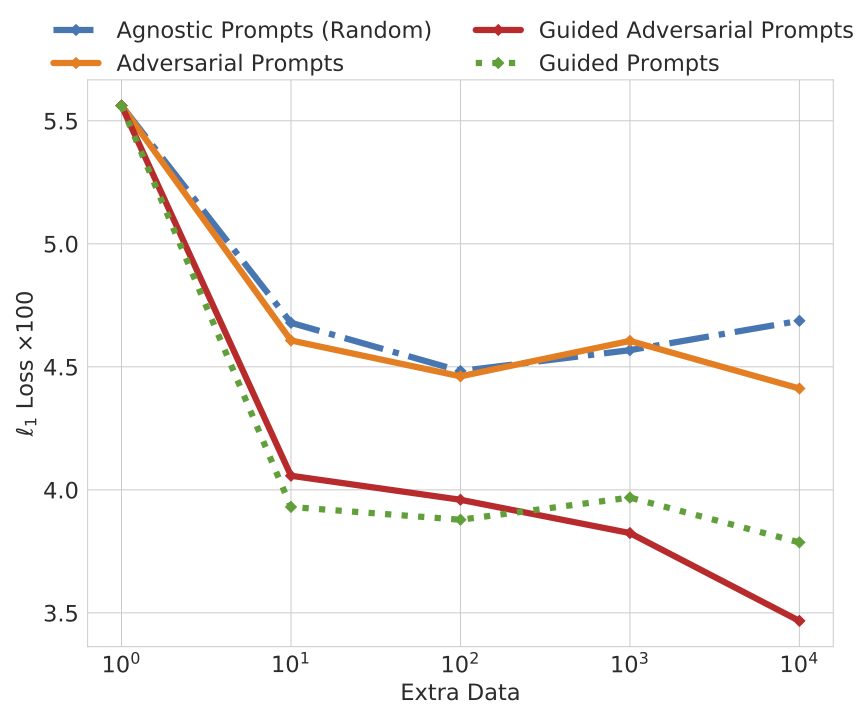
x-axis: the amount of extra data generated. y-axis: \(\ell_1\) errors \((\times 100)\) under defocus blur corruption applied on the Taskonomy test set.
Guided Adversarial Prompts improve the data-efficiency over other methods. We observe that having a guidance mechanism towards the target image distribution consistently improves on top of the Agnostic Prompts baseline (''nature'' prompt). Adversarial Prompts while fooling the model, generate images that are not necessarily relevant to the target distribution and, thus, not useful to adapt the model to it. Combining both mechanisms in Guided Adversarial Prompts leads to improved data efficiency. Unlike Guided Prompts that uses the same prompts to generate images for both classes, GAP finds prompts that generate images the model fails on, this leads to the generation of waterbirds on land and landbirds on water, the combinations not present in the original training data, which are necessary data samples for the model to learn the bird predictive feature.
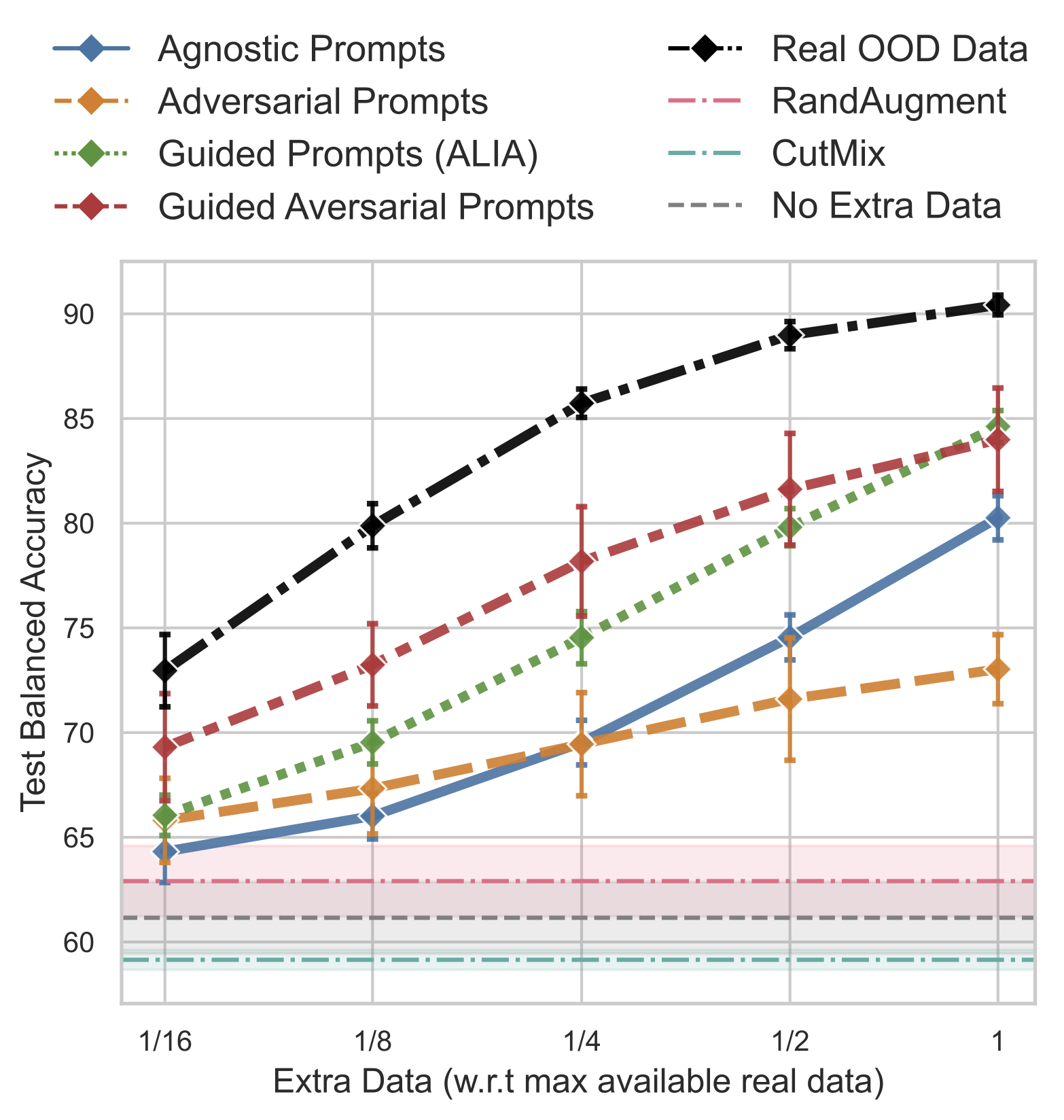
x-axis: the amount of extra data generated. y-axis: the accuracy on the balanced test set (both waterbirds and landbirds on both land and water).
Guided Adversarial Prompts combines the benefits of both model- and target-informed feedback mechanisms, consistently outperforming other methods. Additionally, model-informed feedback (Adversarial Prompts) improves the performance of a target-only informed (Guided Prompts) in the low-data regime.
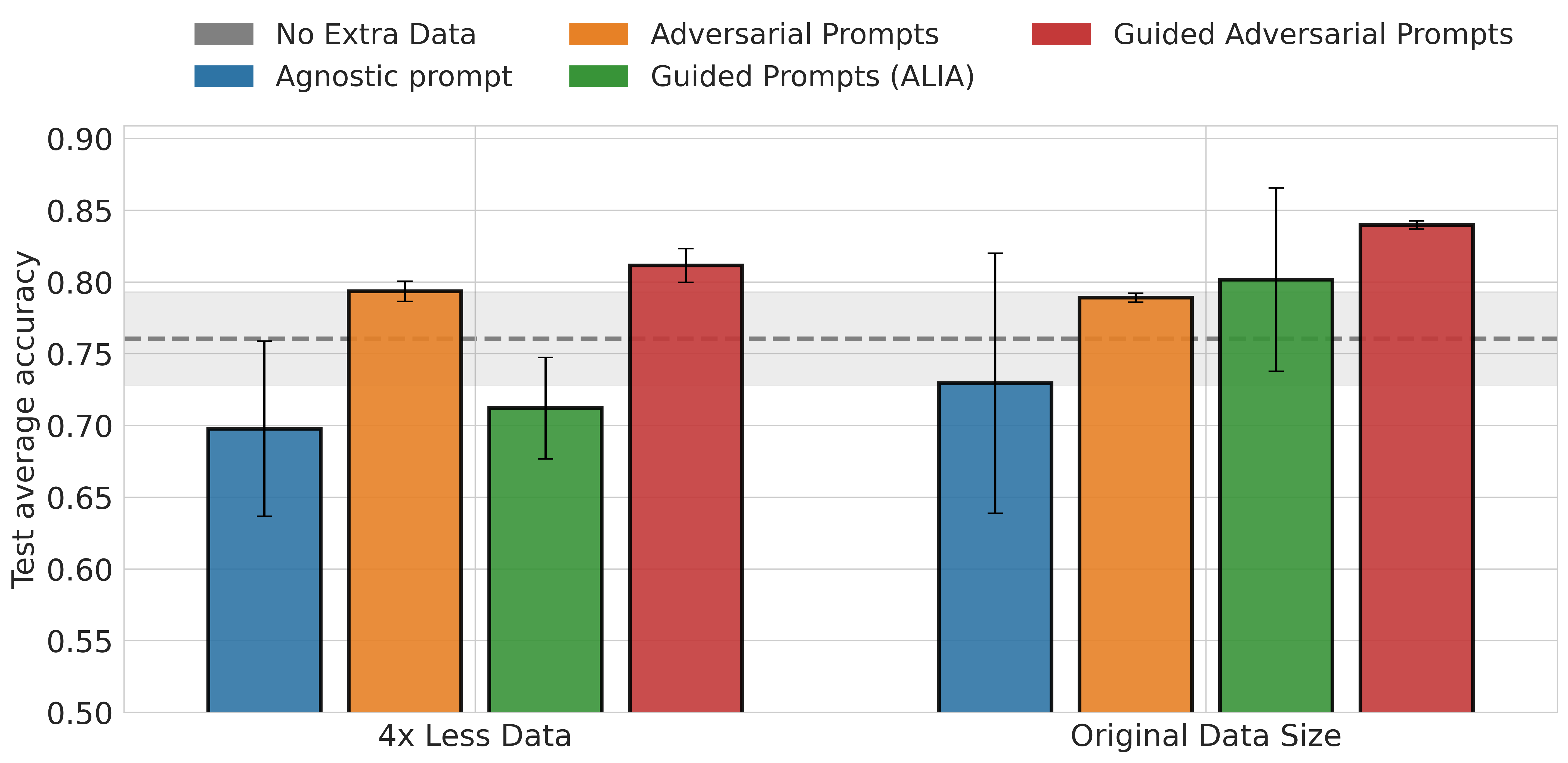
x-axis: the amount of extra data generated. y-axis: average accuracy on 2 test camera trap locations.
• We performed multiple iterations of adversarial optimization → generation → fine-tuning,
and show that using a single iteration is sufficient (see Sec. 4.2.1).
• Results from performing adversarial optimization on different supervised models on the same task (see sup. mat. Sec 3.3 for qualitative results).
• A visual and quantitative comparison of the generations from text and image guidance (see sup. mat. Sec 3.4.2).
@article{yeo@Controlled,
author = {Yeo, Teresa and Atanov, Andrei and Benoit, Harold and Alekseev, Aleksandr and Ray, Ruchira and Esmaeil Akhoondi, Pooya and Zamir, Amir},
title = {Controlled Training Data Generation with Diffusion Models},
journal = {Arxiv},
year = {2023},
}